CMU HCII + Meta
Using LLMs to generate UI components in the Augmented Perception Lab - CMU Human-Computer Interaction Institute - a collaboration with Meta.
Role
Researcher, Developer
Timeline
12 Weeks
Skills
Prototyping
Task Flow
User Tests
Research
Tools
Figma
ChatGPT
MRTK
Unity
Team
Nancy Sun

Research Internship

Augmented Reality and Extended Reality
offers engaging user experiences and has
a broad range of applications. The Augmented Perception Lab developed MineXR, a design mining workflow
and data platform that is used for collecting and analyzing personalized XR user interaction and experiences.
Our work focuses on leveraging the MineXR dataset to develop an LLM pipeline that outputs User Interface components based on an initial given context to create context-aware AR/VR headsets.
The Research Question
How can we develop a personalized context-aware user interface with LLMs, informed by MineXR data?
Research Question
How can we develop a personalized context-aware user interface with LLMs, informed by MineXR data?
Research
Understanding LLM Pipelines
While brainstorming our workflow and developing each LLM agent, we referenced several papers that have generated UI components using LLMs as well as in different contexts.
From the paper BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks, we examined the use of specific LLM agents for the purpose of testing code, making changes, and rendering those changes in a visual interface for the user. While this paper was within the context of teaching coding and programming to users, we examined the LLM agent structure to inform our own pipeline.

We also referred to the paper LLMR: Real-time Prompting of Interactive Worlds using Large Language Models which focuses on the generation of UI components using an LLM pipeline, while also ultimately creating a VR interface. This helped inform us about how to create components in an AR/VR context. One LLM agent we examined to develop in our pipeline was the code generator which can be built in Unity, referencing the Microsoft Mixed Reality Toolkit.

Research
Exploring the MineXR Dataset
I examined the MineXR workflow which enables researchers to collect and analyze users’ personalized XR interfaces in various contexts.
I focused on the MineXR dataset for our integration with LLMs, consisting of 695 XR widgets in 109 unique XR layouts.
*Widgets are defined as cropped app interfaces


From the dataset, I played around with the given contexts (environment + task) and the subsequent widgets and screen descriptions from the dataset. I aimed to fine-tune the dataset into the most ideal form to supplement the LLM.
Exploration
Planning the Workflow
I first explored LLMs and different LLM agents by asking questions, creating prompts of varying specificity, and documenting our findings. Based on these explorations, we developed an initial framework for the pipeline and defined the desired input and output of each LLM agent.
This pipeline contains three initial components:
-
Task Generator: The input is the context which includes the environment and task. The output is a list of tasks that would be useful based on the context
-
Application Planner: The input is the output of the task generator. The output is an example of apps based on the input tasks
-
Functionality Planner: The input is the output of the application planner. The output is a list of functionalities for each app type and a categorization of each app type as primary, periphery, or ambient]

Development
Developing the Pipeline
The goal was to leverage the MineXR dataset within the pipeline to make the outputs (functionalities) more well informed and relatively parallel to the dataset.
To this end, we experimented with introducing the dataset in multiple places in the pipeline
-
as an example within a prompt
-
as a debugger LLM
We then figured out how to implement the dataset into the pipeline with an LLM agent which makes the most sense and produces the most ideal and precise results. This included datasets with a varying number of locations and tasks.

Experimentation
Testing and Optimization
I first developed a score for quantifying the quality of our output to compare how well the pipeline produced outputs. This was dependent on three calculations and factors. One was the overlap of app categories in the functionality output. Another being the semantic similarity of the functionalities themselves. The last factor is the primary overlap of apps in the LLM output and the Dataset.
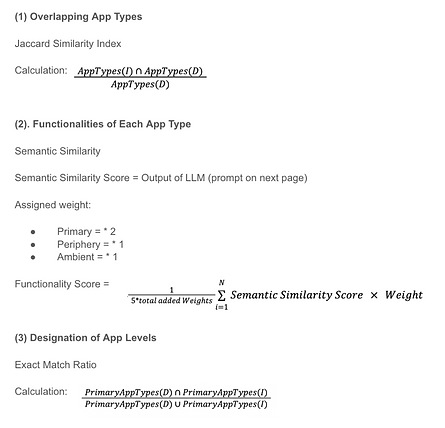
We created our pipeline tests and developed comparisons between modified LLM agents, prompts, and factors such as number of apps, app types, functionality descriptions, and categorization into primary, periphery, and ambient layouts.
More to come soon...